

Pxp_document is hard to read without some background
information. This introduction is supposed to provide this information.
Also note that there is also a stream representation of XML. See
Intro_events for more about this.
In a document parsed with the default parser settings every node
represents either an element or a character data section. There are
two classes implementing the two aspects of nodes:
Pxp_document.element_impl, and
Pxp_document.data_impl. There are configurations which
allow more node types to be created, in particular processing
instruction nodes, comment nodes, and super root nodes, but these are
discussed later. Note that you can always add these extra node types
yourself to the node tree no matter what the parser configuration
specifies.
The following figure
shows an example how
a tree is constructed from element and data nodes. The circular areas
represent element nodes whereas the ovals denote data nodes. Only elements
may have subnodes; data nodes are always leaves of the tree. The subnodes
of an element can be either element or data nodes; in both cases the O'Caml
objects storing the nodes have the class type Pxp_document.node.
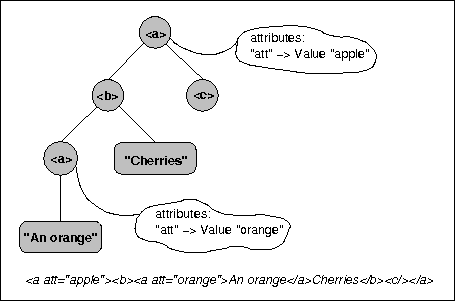
Attributes (the clouds in the picture) do not appear as nodes of the tree, and one must use special access methods to get them.
You would get such a tree by parsing with
let config = Pxp_types.default_config
let source = Pxp_types.from_string
"An orangeCherries
The config record sets a lot of parsing options. A number of these
options are explained below. The source argument says from where
the parsed text comes. For the mysterious spec parameter see below.
The parser returns doc, which is a Pxp_document.document. You
have to call its root method to get the root of the tree. Note that
there are other parsing functions that return directly nodes; these
are intended for parsing XML fragments, however. For the usual closed
XML documents use a function that returns a document.
The root is, as other nodes of the tree, an object instance of the
Pxp_document.node class type.
What about other things that can occur in XML text? As mentioned,
by default only elements and data nodes appear in the tree, but it is
possible to enable more node types by setting appropriate
Pxp_types.config options:
enable_comment_nodes, however, comments are added to the tree. There is a
special node type for comments.<? ... ?> parentheses) are
not ignored, but normally no nodes are created for them. The
instructions are only gathered up, and attached to the surrounding
node, so one can check for their
presence but not for their exact location. By setting the
config option enable_pinstr_nodes, however, processing instructions
are added to the tree as normal nodes. There is also a special node
type for them.enable_super_root_node.
The node is called super root node, and is also a special type of node.<![CDATA[some text]]>) are simply added to the
surrounding data node,
so they do not appear as nodes of their own.&) are automatically resolved, and
the resolution is added to the surrounding node
a & b <!-- comment --> c <![CDATA[<> d]]>
is represented by only one data node, for instance (for the default case where no comment nodes are created). Of course, you can create document trees manually which break this invariant; it is only the way the parser forms the tree.
All types of nodes are represented by the same Ocaml objects of
class type Pxp_document.node. The method
Pxp_document.node.node_type returns
a hint which type of node the object is. See the type
Pxp_document.node_type for details how the mentioned node types are
reflected by this method. For instance, for elements this method
returns T_element n where n is the name of the element.
Note that this means formally that all access methods are implemented
for all node types. For example, you can get the attributes of
data nodes by calling the Pxp_document.node.attributes method,
although this does not
make sense. This problem is resolved on a case-by-case basis by
either returning an "empty value" or by raising appropriate
exceptions (e.g. Pxp_types.Method_not_applicable).
For the chosen typing it is not possible to define slimmer class types
that better fit the various node types.
Attributes are usually represented as pairs
string * att_value of names and values. Here,
Pxp_types.att_value is a conventional variant type. There are lots of
access methods for attributes, see below. It is optionally possible
to wrap the attributes as nodes (method
Pxp_document.node.attributes_as_nodes), but even in this case the attributes
are outside the regular document tree.
Normally, the processing instructions are also not included
into the document tree. They are considered as an extra property of the
element to which they are attached, and can be retrieved by the
Pxp_document.node.pinstr
method of the element node. If this way of handling processing instructions
is not exact enough, the parser can optionally create processing instruction
nodes that are regular members of the document tree.
An overview over some relevant access methods:
dtd (Pxp_document.node.dtd): returns the DTD object.
All nodes have such an object, even in well-formed mode.encoding (Pxp_document.node.encoding): returns the
encoding of the in-memory document representation.parent (Pxp_document.node.parent): returns the parent object
of the node it is called onroot (Pxp_document.node.root): returns the root of the tree
the node is member ofsub_nodes (Pxp_document.node.sub_nodes): returns the children
of the node previous_node (Pxp_document.node.previous_node): returns the
left siblingnext_node (Pxp_document.node.next_node): returns the
right siblingnode_position (Pxp_document.node.node_position): returns the
ordinal position of this node as child of the parentnode_path (Pxp_document.node.node_path): returns the positional
path of this node in the whole treenode_type (Pxp_document.node.node_type): returns the type of
the nodeposition (Pxp_document.node.position): returns the position
of the node in the parsed XML textdata (Pxp_document.node.data): returns the data contents of
data nodesattributes (Pxp_document.node.attributes): returns the attributes
of elementsattributes_as_nodes (Pxp_document.node.attributes_as_nodes):
also returns the attributes, but represented as a list of nodes
residing outside the tree comment (Pxp_document.node.comment): returns the text of the
XML comment validate (Pxp_document.node.validate): validates the element
locally localname (Pxp_document.node.localname): returns the local name
of the element in the namespace namespace_uri (Pxp_document.node.namespace_uri): returns the
namespace URI of the node namespace_scope (Pxp_document.node.namespace_scope): returns
the scope object with more namespace query methods namespaces_as_nodes (Pxp_document.node.namespaces_as_nodes):
returns the namespaces this node is member of, and the namespaces
are represented as list of nodes
Trees are mutable, and nodes are mutable. Note that the tree is not
automatically (re-)validated when it is changed. You have to explicitly
call validation methods, or the Pxp_document.validate function for the
whole tree.
append_node (Pxp_document.node.append_node): appends a
node as new child to this node remove (Pxp_document.node.remove): removes this node from
the tree set_data (Pxp_document.node.set_data): changes the contents
of data nodes set_attribute (Pxp_document.node.set_attribute): adds or
changes an attribute set_comment (Pxp_document.node.set_comment): changes the
contents of comment nodes create_element (Pxp_document.node.create_element):
called on an element node, this method creates a new tree only
consisting of an element, and the only node of the tree is an
object of the same class as this nodecreate_data (Pxp_document.node.create_data): same for data
nodes orphaned_clone (Pxp_document.node.orphaned_clone):
creates a copy of the subtree starting at this node The node tree has links in both directions: Every node has a link to its parent (if any), and it has links to the subnodes (see the following picture). Obviously, this doubly-linked structure simplifies the navigation in the tree; but has also some consequences for the possible operations on trees.
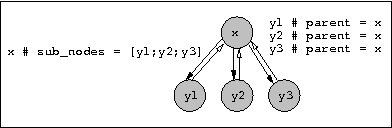
(Definitions: Pxp_document.node.parent, Pxp_document.node.sub_nodes.)
Because every node must have at most one parent node,
operations are illegal if they violate this condition. The following figure
shows on the left side
that node y is added to x as new subnode
which is allowed because y does not have a parent yet. The
right side of the picture illustrates what would happen if y
had a parent node; this is illegal because y would have two
parents after the operation.
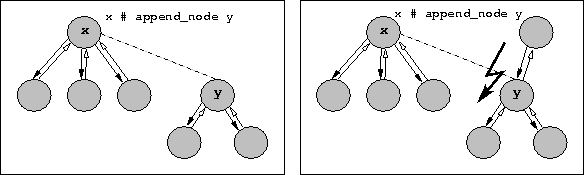
(Definition: Pxp_document.node.append_node.)
The remove operation simply removes the links between two nodes. In the
following picture the node
x is deleted from the list of subnodes of
y. After that, x becomes the root of the
subtree starting at this node.
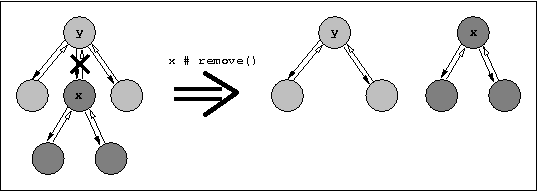
(Definition: Pxp_document.node.remove.)
It is also possible to make a clone of a subtree; illustrated in the next picture. In this case, the clone is a copy of the original subtree except that it is no longer a subnode. Because cloning never keeps the connection to the parent, the clones are called orphaned.
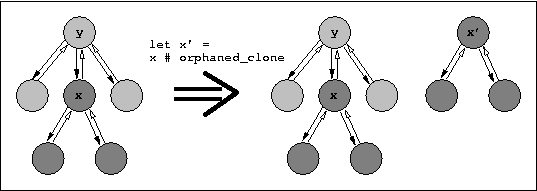
(Definition: Pxp_document.node.orphaned_clone.)
As already pointed out, the parser does only create element and data nodes by
default. The configuration of the parser can be controlled by the
Pxp_types.config record. There are a number of optional features that
change the way the document trees are constructed by the parser:
Note that the parser configuration only controls the parser. If you create trees of your own, you can simply add all the additional node types to the tree without needing to enable these features.
enable_super_root_node is set, the extra super root node
is generated at the top of the tree. This node has type T_super_root.enable_comment_nodes lets the
parser add comment nodes when it parses comments. These nodes have
type T_comment.enable_pinstr_nodes changes the
way processing instructions are added to the document. Instead of attaching
such instructions to their containing elements as additional properties, this
mode forces the parser to create real nodes of type T_pinstr for them.drop_ignorable_whitespace (enabled by default) can
be turned off. It controls whether the parser skips over so-called ignorable
whitespace. The XML standard allows that elements contain whitespace
characters even if they are declared in the DTD not to contain character data.
Because of this, the parser considers such whitespace as ignorable detail
of the XML instance, and drops the characters silently. You can change
this by setting drop_ignorable_whitespace to false. In
this case, every character of the XML instance will be accepted by the
parser and will be added to a data node of the document tree.position. As this requires a lot of
memory, it is possible to turn this off by setting
store_element_positions to false.There are a number of further configuration options; however, these options do not change the structure of the document tree.
The following features exist per node, and are simply invoked by using the methods dealing with them.
attributes_as_nodes returns the attributes wrapped into node
objects. Note that these nodes are read-only.The DTD object contains the declarations of elements, attribute lists, entities, and notations. Furthermore, the DTD knows whether the document is flagged as "standalone". As a PXP extension to classic XML processing, the DTD may specify a mixed mode between "validating mode" and "well-formedness mode". It is possible to allow non-declared elements in the document, but to check declared elements against their declaration at the same time. Moreover, there is a similar feature for attribute lists; you can allow non-declared attributes and check declared attributes. (Well, the whole truth is that the parser always works in this mix mode, and that the "validating mode" and the "well-formedness mode" are only the extremes of the mix mode.)
Often, the parser creates the trees, but on occasion it is useful to create trees manually. We explain here only the basic mechanism. There is a nice camlp4 syntax extension called pxp-pp (XXX: LINK) allowing for a much better notation in programs.
The most basic way of creating new nodes are the create_element,
create_data, and create_other methods of nodes. It is not recommended
to use them directly, however, as they are very primitive.
In the Pxp_document module there are a number of functions creating
individual nodes (without children), the node constructors:
Pxp_document.create_element_node: creates an element nodePxp_document.create_data_node: creates a data nodePxp_document.create_comment_node: creates a comment nodePxp_document.create_pinstr_node: creates a processing instruction nodePxp_document.create_super_root_node: creates a super root nodeThe node constructors must be equipped with all required data to create the requested type of node. This includes the data that would have been available in the textual XML representation, and some of the meta data passed to the parsers, and meta data implicitly generated by the parsers. For an element, this is at minimum:
<foo>)
After some nodes have been created, they can be combined to more complex
trees by mutation methods (e.g. Pxp_document.node.append_node).
As mentioned, a node must always be connected with a DTD object, even if no validation checks will be done. It is possible to create DTD objects that do not impose restrictions on the document:
let dtd = Pxp_dtd_parser.create_empty_dtd config
dtd # allow_arbitrary
Even such a DTD object can contain entity definitions, and can demand
a certain way of dealing with namespaces. Also, the character encoding
of the nodes is taken from the DTD. See Pxp_dtd.dtd for
DTD methods, and Pxp_dtd_parser for convenient ways to create DTD
objects. Note that all nodes of a tree must be connected to the same
DTD object.
PXP is not restricted to using built-in classes for nodes. When the
parser is invoked and a tree is built, it is looked up in a so-called
document model specification how the new objects have to be
created (type Pxp_document.spec. Basically, it is a list of sample
objects to use (which are called exemplars), and these objects are
cloned when a node is actually created.
When calling the node constructors directly (bypassing the parser), the document model specification has also to be passed to them as argument. It is used in the same way as the parser uses it.
For getting the built-in classes without any modification, just use
Pxp_tree_parser.default_spec. For the variant with enabled namespaces,
prefer Pxp_tree_parser.default_namespace_spec.
Every node in a tree has a so-called extension. By default, the extension is practically empty and only present for formal uniformity. However, one can also define custom extension classes, and effectively add new methods to the node classes.
Node extensions are explained in detail here: Intro_extensions
As an option, PXP processes namespace declarations in XML text.
See this separate introduction for details: Intro_namespaces.
If an element declaration does not allow the element to contain character data, the following rules apply.
If the element must be empty, i.e. it is declared with the
keyword EMPTY, the element instance must be effectively
empty (it must not even contain whitespace characters). The parser guarantees
that a declared EMPTY element never contains a data
node, even if the data node represents the empty string.
If the element declaration only permits other elements to occur within that element but not character data, it is still possible to insert whitespace characters between the subelements. The parser ignores these characters, too, and does not create data nodes for them.
Example. Consider the following element types:
<!ELEMENT x ( #PCDATA | z )* >
<!ELEMENT y ( z )* >
<!ELEMENT z EMPTY>
Only x may contain character data, the keyword
#PCDATA indicates this. The other types are character-free.
The XML term
<x><z/> <z/></x>
will be internally represented by an element node for x
with three subnodes: the first z element, a data node
containing the space character, and the second z element.
In contrast to this, the term
<y><z/> <z/></y>
is represented by an element node for y with only
two subnodes, the two z elements. There
is no data node for the space character because spaces are ignored in the
character-free element y.
Parser option:
By setting the parser option drop_ignorable_whitespace to
false, the behaviour of the parser is changed such that
even ignorable whitespace characters are represented by data nodes.
The XML specification allows all Unicode characters in XML
texts. This parser can be configured such that UTF-8 is used to represent the
characters internally; however, the default character encoding is
ISO-8859-1. (Currently, no other encodings are possible for the internal string
representation; the type Pxp_types.rep_encoding enumerates
the possible encodings. Principally, the parser could use any encoding that is
ASCII-compatible, but there are currently only lexical analyzers for UTF-8 and
ISO-8859-1. It is currently impossible to use UTF-16 or UCS-4 as internal
encodings (or other multibyte encodings which are not ASCII-compatible) unless
major parts of the parser are rewritten - unlikely...)
The internal encoding may be different from the external encoding (specified
in the XML declaration <?xml ... encoding="..."?>); in
this case the strings are automatically converted to the internal encoding.
If the internal encoding is ISO-8859-1, it is possible that there are
characters that cannot be represented. In this case, the parser ignores such
characters and prints a warning (to the collect_warning
object that must be passed when the parser is called).
The XML specification allows lines to be separated by single LF characters, by CR LF character sequences, or by single CR characters. Internally, these separators are always converted to single LF characters.
The parser guarantees that there are never two adjacent data nodes; if necessary, data material that would otherwise be represented by several nodes is collapsed into one node. Note that you can still create node trees with adjacent data nodes; however, the parser does not return such trees.
Note that CDATA sections are not represented specially; such sections are added to the current data material that is being collected for the next data node.
Entities are not represented within documents! If the parser finds an entity reference in the document content, the reference is immediately expanded, and the parser reads the expansion text instead of the reference.
As attribute values are composed of Unicode characters, too, the same problems with the character encoding arise as for character material. Attribute values are converted to the internal encoding, too; and if there are characters that cannot be represented, these are dropped, and a warning is printed.
Attribute values are normalized before they are returned by
methods like attribute. First, any remaining entity
references are expanded; if necessary, expansion is performed recursively.
Second, newline characters (any of LF, CR LF, or CR characters) are converted
to single space characters. Note that especially the latter action is
prescribed by the XML standard (but is not converted
such that it is still possible to include line feeds into attributes).
Processing instructions are parsed to some extent: The first word of the PI is called the target, and it is stored separated from the rest of the PI:
<?target rest?>
The exact location where a PI occurs is not represented (by default). The parser attaches the PI to the object that represents the embracing construct (an element, a DTD, or the whole document); that means you can find out which PIs occur in a certain element, in the DTD, or in the whole document, but you cannot lookup the exact position within the construct.
Parser option:
If you require the exact location of PIs, it is possible to
create regular nodes for them instead of attaching them to the surrounding
node as property. This mode is controlled by the option
enable_pinstr_nodes. The additional nodes have the node type
T_pinstr target, and are created
from special exemplars contained in the spec (see
Pxp_document.spec).
Normally, comments are not represented; they are dropped by default.
Parser option:
However, if you require comment in the document tree, it is possible to create
T_comment nodes for them. This mode can be specified by the
option enable_comment_nodes. Comment nodes are created from
special exemplars contained in the spec (see
Pxp_document.spec). You can access the contents of comments through the
method comment.
xml:lang and xml:space These attributes are not supported specially; they are handled like any other attribute.
Note that the utility function
Pxp_document.strip_whitespace respects xml:space
